以前、Docurainが「外字」または異体字セレクタ(IVS)に対応済みであることお知らせしましたが、 Unicode絵文字の出力と絵文字に対しての文字列操作も対応しています。
早速、絵文字を出力してみよう
テンプレート・JSONは以下のように作成しています。
テンプレート

JSON
{
"農家": "👩🌾",
"家族": "👨👩👧",
"One": "1️⃣",
"自転車": "🚵♀️",
"国旗": "🇯🇵🇯🇵🇯🇵",
"農家_es": "\ud83d\udc69\u200d\ud83c\udf3e",
"家族_es": "\ud83d\udc68\u200d\ud83d\udc69\u200d\ud83d\udc67",
"One_es": "1\ufe0f\u20e3",
"自転車_es": "\ud83d\udeb5\u200d\u2640\ufe0f",
"国旗_es": "\ud83c\uddef\ud83c\uddf5\ud83c\uddef\ud83c\uddf5\ud83c\uddef\ud83c\uddf5",
"農家_ucd": "\\U+D83D\\U+DC69\\U+200D\\U+D83C\\U+DF3E",
"家族_ucd": "\\U+D83D\\U+DC68\\U+200D\\U+D83D\\U+DC69\\U+200D\\U+D83D\\U+DC67",
"One_ucd": "\\U+0031\\U+FE0F\\U+20E3",
"自転車_ucd": "\\U+D83D\\U+DEB5\\U+200D\\U+2640\\U+FE0F",
"国旗_ucd": "\\U+D83C\\U+DDEF\\U+D83C\\U+DDF5\\U+D83C\\U+DDEF\\U+D83C\\U+DDF5\\U+D83C\\U+DDEF\\U+D83C\\U+DDF5"
}
JSONはこのようになります。 以下のそれぞれで設定が可能です。
- 絵文字
- Unicodeエスケープシーケンス
- Unicode(UTF-16)
上記テンプレート・JSONで出力してみましょう。

問題なく絵文字が出力されています。(macOS上のExcel)
ただし、Windows版のExcelやPDFでは以下のように表示されます。
| Windows Excel | |
|---|---|
 |
 |
このように、Docurainとしては絵文字の出力に対応していますが、 表示する側がまだ対応できていないことがあります。
絵文字の文字列操作
次にこの絵文字に対しての文字列操作です。
例えば
"🍣と🍺".length
とJavascriptで実行すると、3ではなく5が返ってきます。
これは↓の以前のブログでもご紹介している通り、🍣や🍺はサロゲートペアであるためです。 blog.docurain.jp
また、"👨👩👧と🏖".length や "👩❤️👨で🎡".length は どちらも11となります。
これは 👨👩👧 や 👩❤️👨 は
👨👨👦 = 👨 + 👧 + 👩
👩❤️👩 = 👩 + ❤️ + 👩
のようにできている絵文字だからです。
"🍣と🍺".length
"👨👨👦と🏖".length
"👩❤️👨で🎡".length
いずれも3が欲しいですよね...
対応してます!
Docurain独自の関数
Docurain独自の関数u_lengthを使えばOKです。
実際に確認してみましょう。
- テンプレート

- JSON
{
"arg1": "🍣と🍺",
"arg2": "👨👩👧と🏖",
"arg3": "👩❤️👨で🎡"
}
- 出力結果
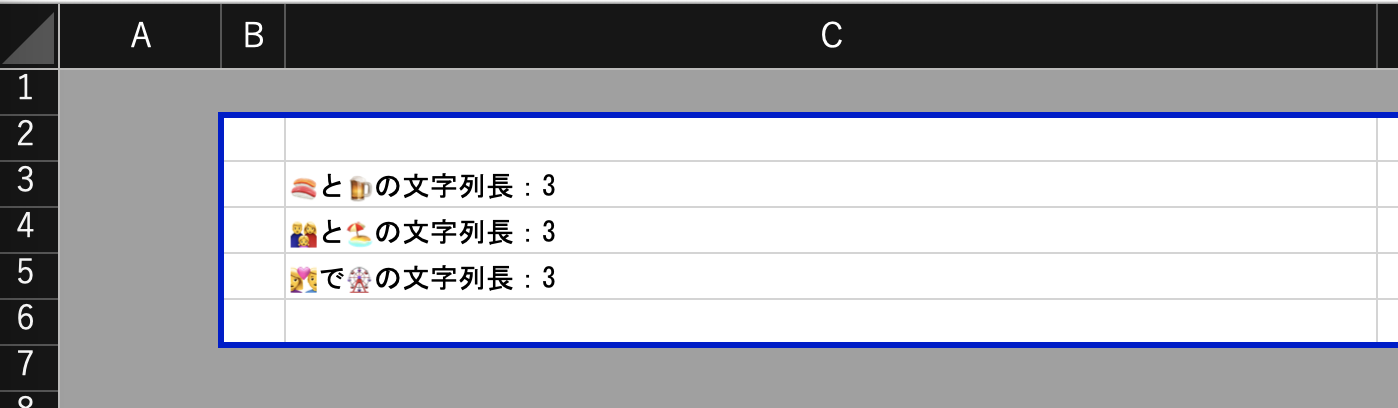
それぞれ3となりましたね!見た目上の文字数でカウントすることができました。
Docurainでは、以下のようなユニコード専用の文字列操作を用意しています。 JSONで送ったデータの文字列オブジェクトのメソッドとして呼び出すことができます。
| 関数名 | 説明 |
|---|---|
| u_length | ユニコードを考慮した文字列長を返す。サロゲートペアや異体字セレクタなどの 書記素クラスタ(grapheme cluster) の文字を全て1文字とカウントする。例えば"🍣と🍺と䄂\uDB40\uDD01"の長さは5とカウントする。 |
| u_charAt(int index) | ユニコードを考慮した文字取得メソッド。オリジナルのString#charAtとは異なり、このメソッドの戻り値は「1文字」を表す文字列になる。書記素クラスタの文字は1文字とカウントする |
| u_toCharArray() | ユニコードを考慮して文字列を文字に分解する。オリジナルのString#toCharArrayとは異なり、このメソッドの戻り値は「1文字」を表す文字列の配列になる。書記素クラスタの文字は1文字とカウントする。 例えば `'🍣と䄂\uDB40\uDD01'`.u_toCharArray()の結果は["🍣","と","䄂\uDB40\uDD01"]になる |
| u_substring(int from), u_substring(int from, int to) | ユニコードを考慮した部分文字列取得メソッド。書記素クラスタの文字は1文字とカウントする |
| u_hasIVS() | 異体字セレクタを含む文字列か判定する |
| u_removeIVS() | 異体字セレクタを除去して通常の字体のみにする |
最低限必要なものは用意しましたが、不足がありましたら随時追加していきます。
絵文字やを扱う帳票作成が必要な際はぜひ試してみてください!
他にも様々な機能がありますので、ぜひアカウント無料登録してマニュアルを参照しお試しください。