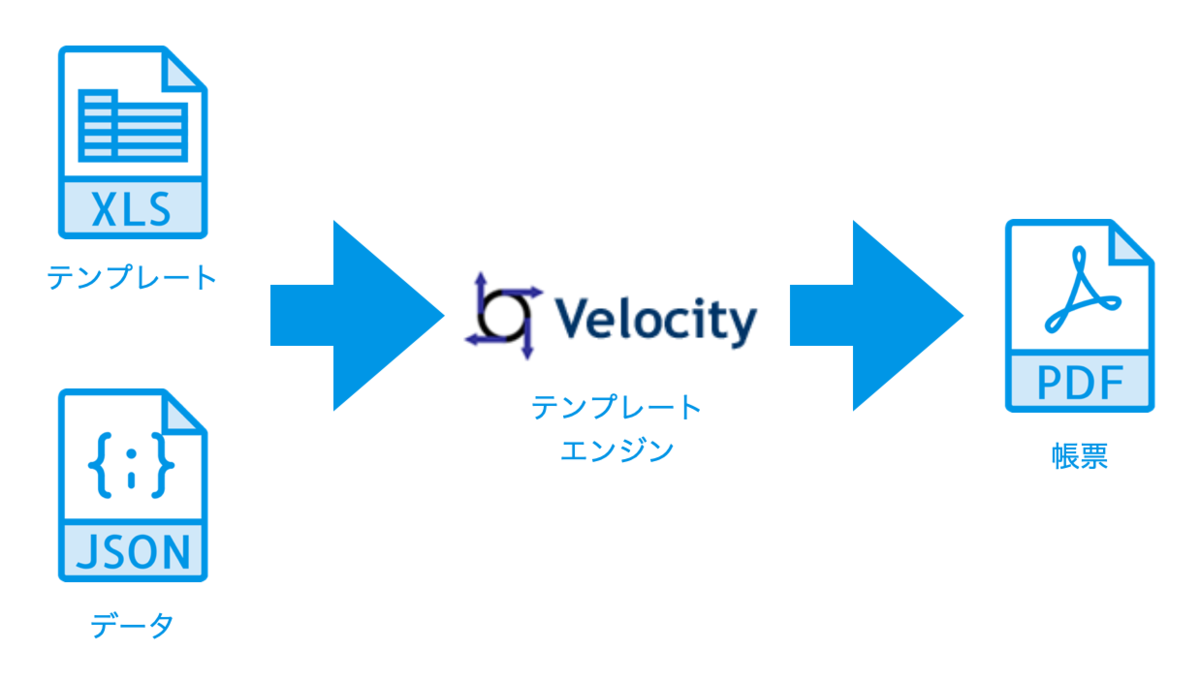
DocurainはExcelファイルをテンプレートとし、さらに描画するデータを与えて帳票やレポートを作成します。与えるデータフォーマットはJSONが一般的なのですが、CSVやTSVも利用可能です。
今回はCSVファイルを使った請求書作成について解説します。
CSVファイルについて
今回利用するCSVファイルは次のようになっています(抜粋です)。企業名、個人名、住所、郵便番号はダミーで生成したものになります。
#no,date,companyname,accountname,address,zipcode,tel,note,item,price,total,tax,totalPrice
1,2021/11/30,有限会社 渚,吉田 浩,岐阜県藤本市斉藤町鈴木3-9-7,215-9066,080-8054-8454,"いつもお世話になります。
2021年11月分の請求書になります。",製品1,4000,14500,1450,15950
1,2021/11/30,有限会社 渚,吉田 浩,岐阜県藤本市斉藤町鈴木3-9-7,215-9066,080-8054-8454,"いつもお世話になります。
2021年11月分の請求書になります。",製品2,6000,14500,1450,15950
:
3,2021/11/30,有限会社 木村,青田 香織,山形県加藤市吉田町加藤9-6-7,167-2711,090-2125-2506,お世話になります。よろしくお願いいたします。,アイテム1,1300,9000,900,9900
3,2021/11/30,有限会社 木村,青田 香織,山形県加藤市吉田町加藤9-6-7,167-2711,090-2125-2506,お世話になります。よろしくお願いいたします。,アイテム2,1000,9000,900,9900
3,2021/11/30,有限会社 木村,青田 香織,山形県加藤市吉田町加藤9-6-7,167-2711,090-2125-2506,お世話になります。よろしくお願いいたします。,アイテム3,6700,9000,900,9900b
ここで注意して欲しい点は以下になります。
- ヘッダー行を定義する場合には
# を最初に記述する
- 帳票をまとめるユニークキー(今回はno)を用意する
- すべての明細行に帳票のヘッダー情報を記述する
ヘッダー行を定義する場合には # を最初に記述する
たとえば次のようなCSVファイルがあったとします(#がないパターンです)。
no,date,name
1,2021-04-01,テスト 太郎
2,2021-05-01,テスト 花子
3,2021-06-01,テスト 次郎
これをDocurainのデータファイルとして適用した場合 $ENTITIES は次のように送られてきます。
[
["no", "date", "name"],
["1", "2021-04-01", "テスト 太郎"],
["2", "2021-05-01", "テスト 花子"],
["3", "2021-06-01", "テスト 次郎"]
]
それに対して、最初に # を付けた場合の $ENTITIES は次のようになります。
[
{
"no": 1, "date": "2021-04-01", "name": "テスト 太郎",
},
{
"no": 2, "date": "2021-05-01", "name": "テスト 花子",
},
{
"no": 3, "date": "2021-06-01", "name": "テスト 次郎",
},
]
後者のヘッダーを設定した場合、 $ENTITIES[0].no のようにアクセスできます。CSVにはヘッダーのような概念がないので、注意してください。
帳票をまとめるユニークキー(今回はno)を用意する
この後のテンプレート側の処理で紹介しますが、どこからどこまでが同じ帳票であるか区別できる必要があります。今回は no という列を持たせて、そこで次の帳票になった時に数字を変更しています。
すべての明細行に帳票のヘッダー情報を記述する
CSVは多段構造は表現できません。そのため帳票ヘッダー、明細のように出力する際には、どちらの情報も一行の中に入れてしまうのがお勧めです。明細行の中に、ヘッダー情報も繰り返し入れてしまうことで、一部を取り出してヘッダー行情報として利用できます。つまり次のような形です。
#set($header = $ENTITIES[0])
テンプレートについて
今回はMicrosoft Officeで提供されている請求書テンプレートを利用します。

テンプレートの実装

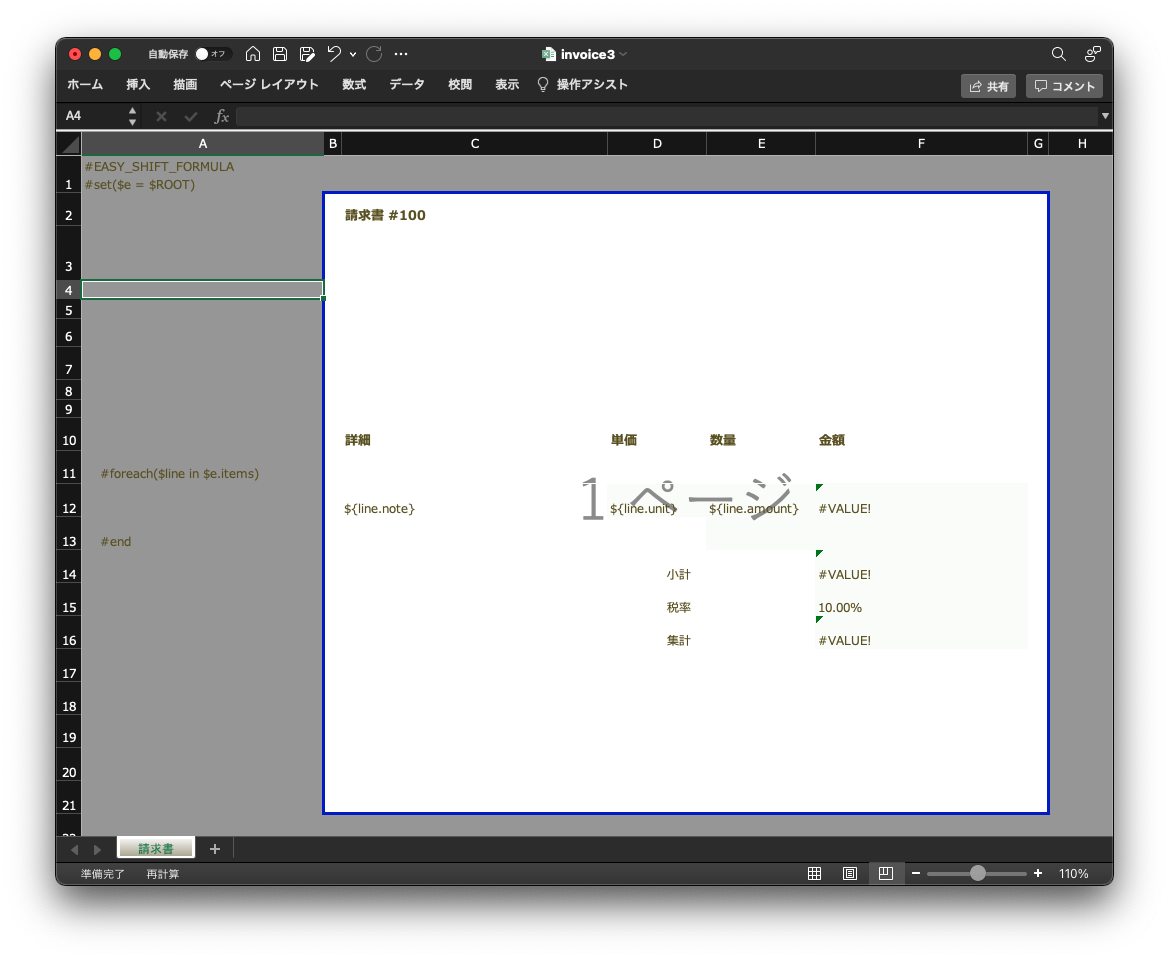
まずA1セルにて、テンプレートで利用するデータの変数を定義し、さらに帳票ごとにグルーピングします。
#set($e = $ENTITIES)
#set($pages = $e.chunk('no'))
$e.chunk('no') を実行すると、ある特定のカラム(今回はno)が同じデータは同じ配列グループになります。元データは $e は次のようになっていると考えてください。
[
{
"no": 1, "date": "2021-04-01", "name": "テスト 太郎",
},
{
"no": 1, "date": "2021-05-01", "name": "テスト 太郎",
},
{
"no": 2, "date": "2021-06-01", "name": "テスト 花子",
},
{
"no": 2, "date": "2021-07-01", "name": "テスト 花子",
},
{
"no": 2, "date": "2021-08-01", "name": "テスト 花子",
},
{
"no": 3, "date": "2021-09-01", "name": "テスト 次郎",
},
{
"no": 3, "date": "2021-10-01", "name": "テスト 次郎",
},
]
このデータに対して $e.chunk('no') を実行すると、次のように変換されます。
[
[
{
"no": 1, "date": "2021-04-01", "name": "テスト 太郎",
},
{
"no": 1, "date": "2021-05-01", "name": "テスト 太郎",
}
],
[
{
"no": 2, "date": "2021-06-01", "name": "テスト 花子",
},
{
"no": 2, "date": "2021-07-01", "name": "テスト 花子",
},
{
"no": 2, "date": "2021-08-01", "name": "テスト 花子",
}
],
[
{
"no": 3, "date": "2021-09-01", "name": "テスト 次郎",
},
{
"no": 3, "date": "2021-10-01", "name": "テスト 次郎",
}
]
]
このようにグルーピングされれば、後はこのグループ毎に帳票を作成するだけです。
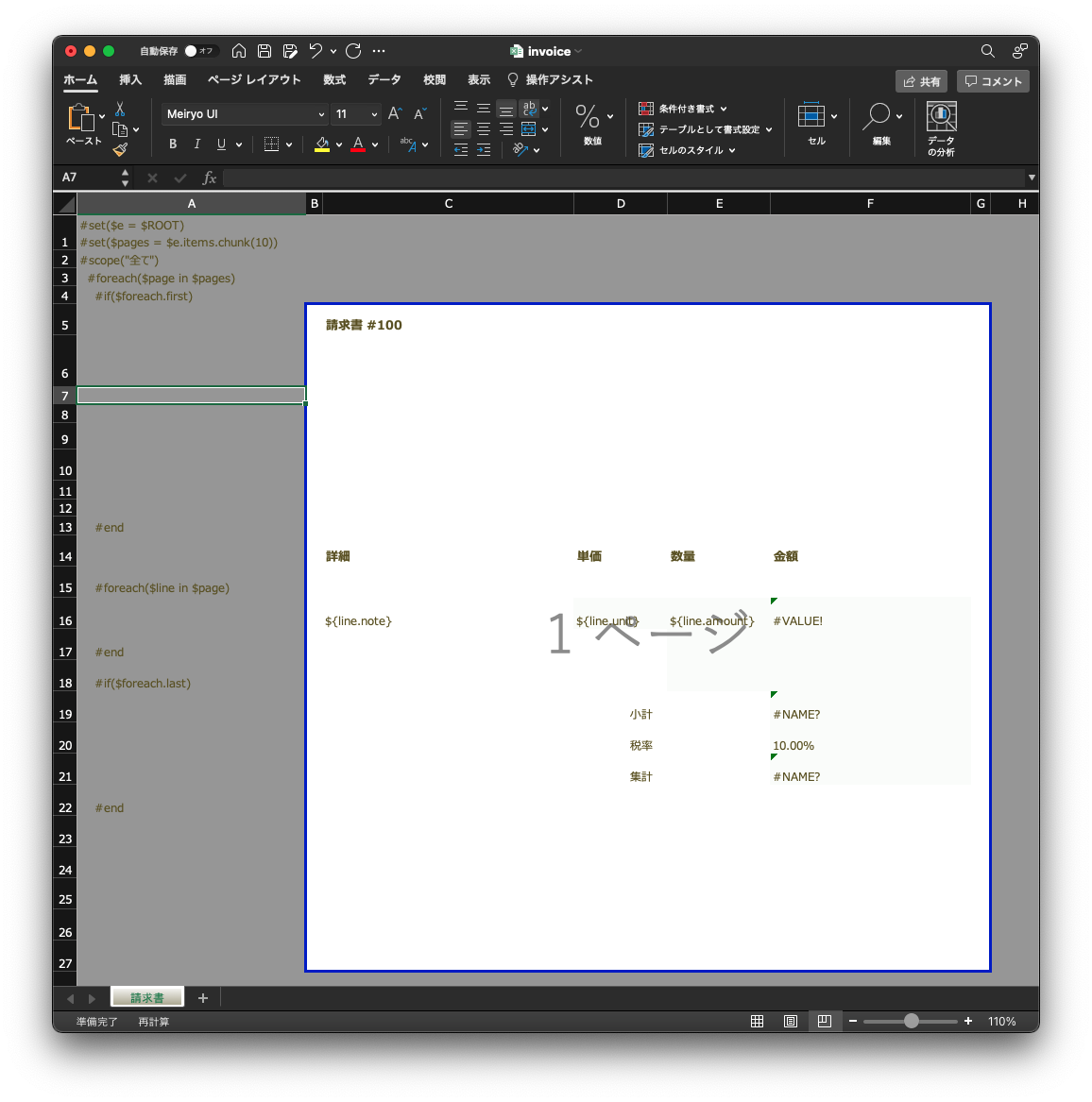
グループ毎の繰り返し
グルーピングできたら、そのグループ毎に処理を行います。つまり foreach を使います。$pageにはグルーピングされたCSV行が入ります。
#foreach($page in $pages)
// この中で帳票の処理
#end
つまり最初の $page は以下のようになっていると考えてください。
[
{
"no": 1, "date": "2021-04-01", "name": "テスト 太郎",
},
{
"no": 1, "date": "2021-05-01", "name": "テスト 太郎",
}
]
ヘッダーの定義
帳票のヘッダーとして利用するデータを抽出します。1行目は必ず存在しますので、添え字として [0] を利用します。
#set($h = $page[0])
ヘッダー行に関するデータ、たとえば会社名などは ${h.companyname} で出力できます。

明細行の処理
明細行も繰り返しになりますので、foreachを使います。
#foreach($item in $page)
// この中で明細処理
#end

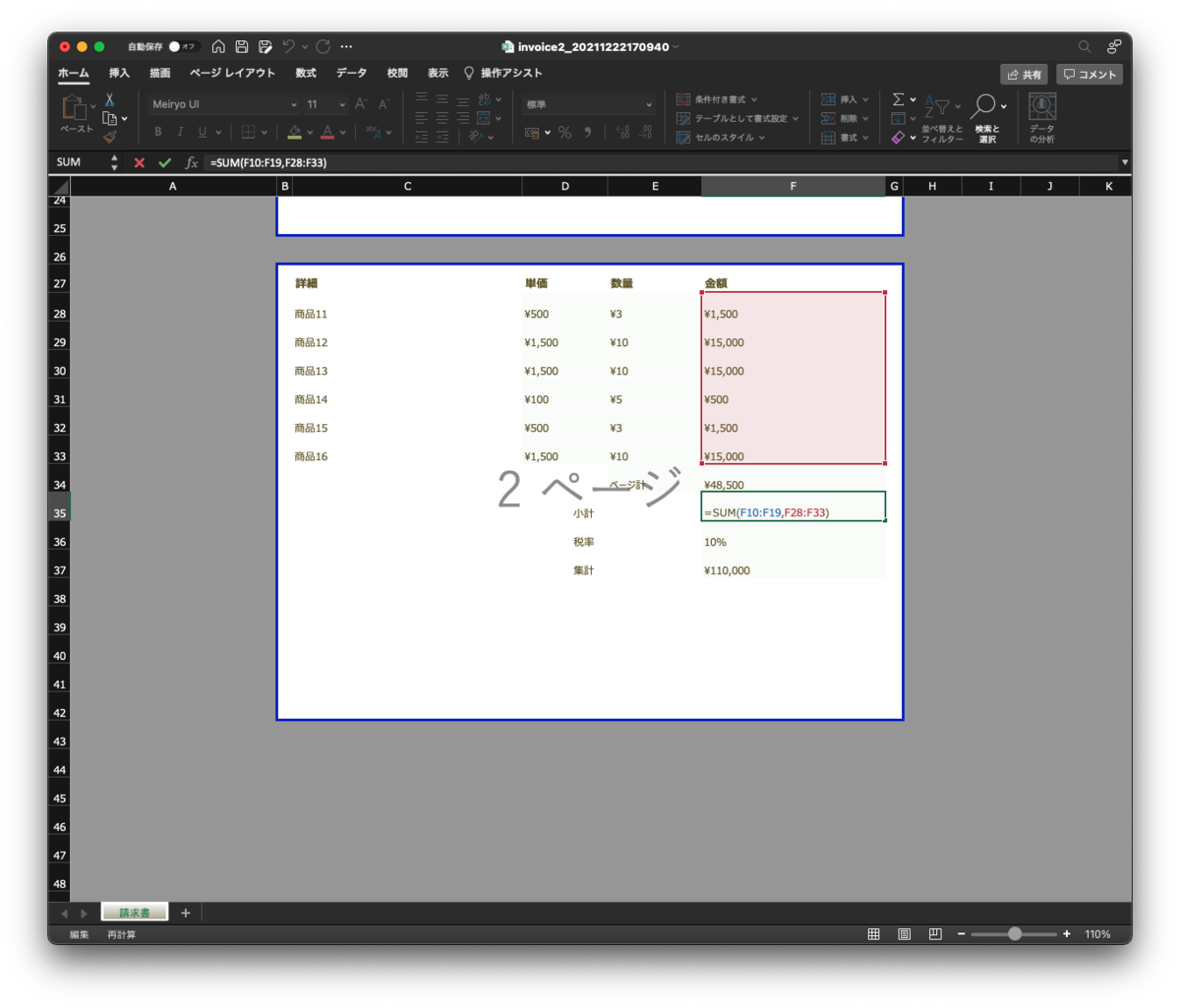
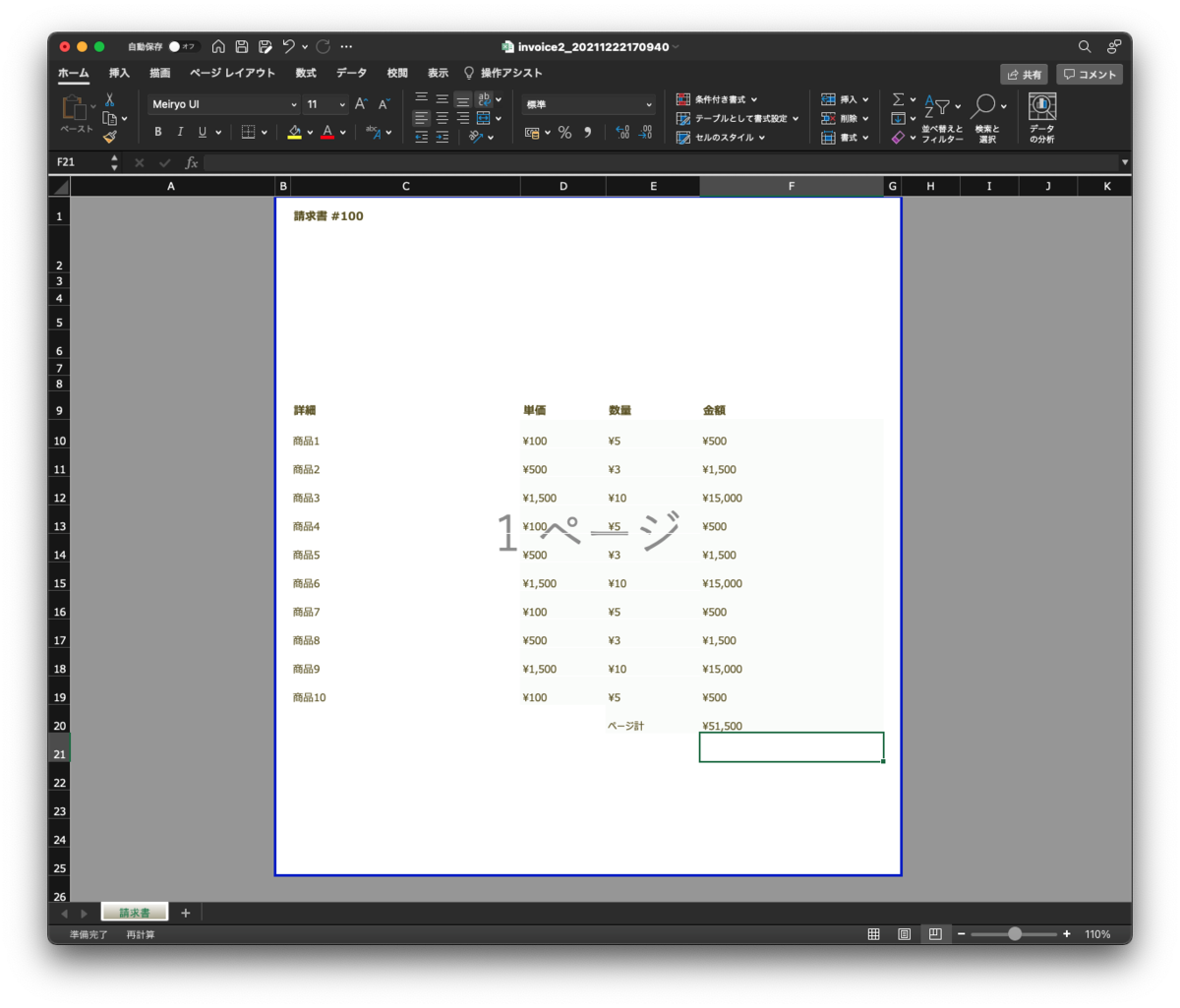
これで帳票のできあがりです。今回はデータの出力のみで、集計計算などは入れていません(CSVデータに元々入れています)。
まとめ
CSVはJSONとはデータ構造が異なるので、その扱いに多少の工夫がいります。しかし、JSONよりも使い慣れている人が多いので、業務システムとの連携ではCSVの方が活躍するかも知れません。
皆さんの帳票作りの参考にしてください。